In part 2 of my post, I'm going to go over huggingface's pytorch transformers library located here.
Huggingface logo
This library provides over 30 pretrained state of the art transformer models on a variety of languages. Alike convolutional neural networks, transformers trained on a different linguistic dataset can be easily retrained on different language datasets. Using pretrained models rather than starting from scratch greatly reduces training time and can sometimes increase accuracy over training a model from scratch.
In this tutorial, I'll be fine-tuning a DistilBert model to predict the sentiment of IMDB movie reviews. DistilBert is a smaller version of the BERT model, allowing it to get most of the performance of BERT for much less training. More details are located in huggingface's blog post.
Implementation
Data Preprocessing
I'm using an IMDB movie reviews dataset, which has a list of movie reviews as well as either a "positive" or "negative" sentiment.
To use huggingface's pretrained models, we have to use their provided tokenizer. Because acquiring the sentiment from a review isn't reliant on stop words such as 'and', 'or', or 'at', we remove them.
from bs4 import BeautifulSoup
from transformers import DistilBertTokenizer
from nltk.corpus import stopwords
stopwords = stopwords.words('english')
distilbert_tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
review = BeautifulSoup(review, "html.parser").get_text()
review = review.lower()
review = distilbert_tokenizer.tokenize(review)
# Remove stopwords/punctuation
review = [w for w in review if w not in stopwords and contains_alphabet(w)]Preprocess data class
Now in the dataset class, we attach the start token [CLF], insert padding, and convert the tokenized words to indicies.
seq_length = 256
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
review = ['[CLF]'] + review[:seq_length - 1]
review = review + ['[PAD]' for _ in range(self.seq_length - len(review))]
review = tokenizer.convert_tokens_to_ids(review)Dataset class
Training
Instantiating the DistilBert model is as simple as importing the class.
model = DistilBertForSequenceClassification.from_pretrained('distilbert-base-uncased', num_labels=2).to('cuda')
lrs = [{'params': model.distilbert.parameters(), 'lr': kwargs['lr_transformer']},
{'params': model.pre_classifier.parameters()},
{'params': model.classifier.parameters()}]
optim = Adam(lrs, lr=kwargs['lr_classifier'], eps=kwargs['eps'])Train class. It may take a while to download the pretrained model. Here, I apply different learning rates to the transformer and classifier to achieve better results.
To train the model, all we have to do is pass the reviews and labels to the model and we get our losses back!
reviews = reviews.to('cuda')
labels = labels.to('cuda').long()
optim.zero_grad()
loss = model(reviews, labels=labels)[0]
loss.backward()
optim.step()Train class. After I get the losses from every minibatch, I backpropagate.
Results
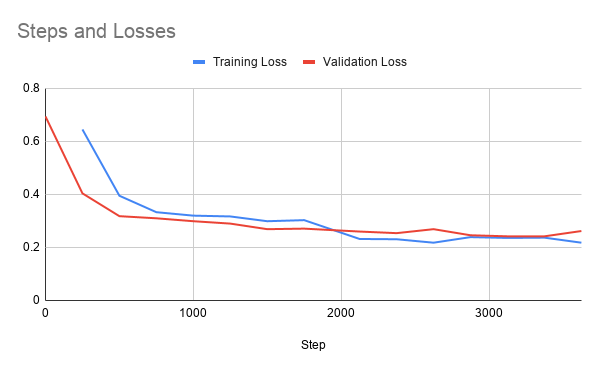
Graph of steps vs loss
After 3 epochs, the pretrained transformer reaches a validation loss of 0.262 and a validation accuracy of 0.9021.
Bar chart of validation accuracy for different models
I trained other common linguistic models including an LSTM and a transformer implemented using nn.Transformer. As shown in the graph, the huggingface transformer still edges out in terms of accuracy.
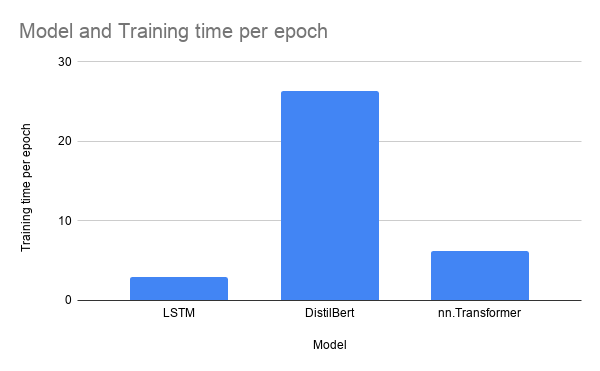
Bar chart of training time per epoch for different models
DistilBert took the longest time to train by far with approximately — min, likely because it has the most amount of parameters. This is followed by nn.Transformer and then by the LSTM.
Further Research
Some further improvements that could be made to this model:
- Improving the dataloader by allowing for variable length batches in order to reduce the amount of wasted memory spent on padding
- Optimizing the parameters further, such as by adding differential learning rates
My code is located here.