In part 1 of my series on transformers, I'm going to go over implementing a neural machine translation model using Pytorch's new nn.Transformer module.

A diagram of the Transformer encoder
Transformers, introduced by the paper Attention is All You Need, inherently don't have a sense of time, They instead rely on positional encoding to encode the order of elements. This gives the transformer architecture an important advantage over other language models such as recurrent neural networks: they are parallelizable and easy to expand. This has allowed huge models such as the 1.5 billion parameter GPT-2 to achieve state of the art performance on language modelling.
Pytorch
Pytorch logo
Now, with the release of Pytorch 1.2, we can build transformers in pytorch! We'll go over the basics of the transformer architecture and how to use nn.Transformer. In a transformer, the input sentence goes through an encoder where the sentence gets passed through encoders to become memory. Then the output sentence and memory passes through decoders where it outputs the translated sentence.
The Encoder

First part of the model
First, we tokenize the input data, pad the array if necessary, and convert the tokens to embeddings.
import spacy
# Tokenize sentence
lang_model = spacy.load('en', disable=['tagger', 'parser', 'ner'])
sentence = sentence.lower()
sentence = [tok.text for tok in lang_model.tokenizer(sentence) if tok.text not in punctuation]
# Create a dictionary which maps tokens to indices (train contains all the training sentences)
freq_list = Counter()
for sentence in train:
freq_list.update(sentence)
# Convert tokens to indices
indices = [freq_list[word] for word in sentence if word in freq_list]Here, I tokenize the sentence using spacy and convert the sentence to indices
import torch
from einops import rearrange
self.embed_src = nn.Embedding(vocab_size, d_model)
src = rearrange(indices, 'n s -> s n')
src = self.embed_src(src)In the LanguageTransformer class, I create an embedding and embed the batch
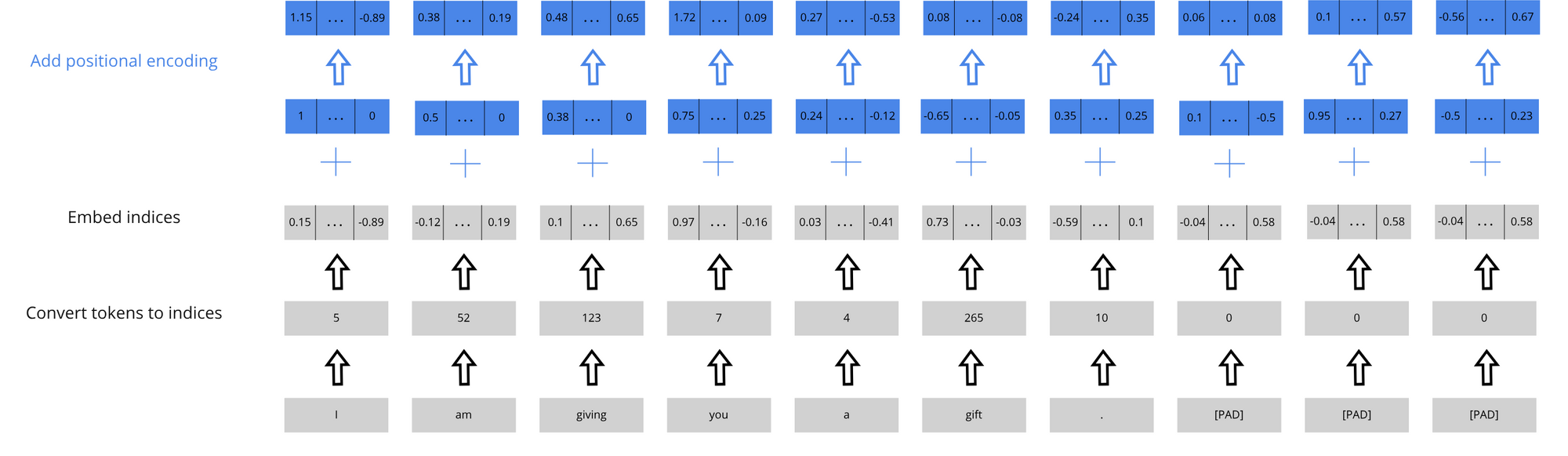
Positional encoding
Now we add the positional encoding to the sentences in order to give some order to the words. In the Attention is All You Need model, they use sine and cosine embeddings to give generalizability to longer sentence sizes.
import math
self.pos_enc = PositionalEncoding(d_model, pos_dropout, max_seq_length)
src = self.pos_enc(src * math.sqrt(self.d_model))In the LanguageTransformer class, I scale src in order to reduce variance then apply the positional encoding
# Source: https://pytorch.org/tutorials/beginner/transformer_tutorial
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=100):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_ter
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return self.dropout(x)PositionalEncoding class

Rest of the encoder
Masking in the encoder is required to make sure any padding doesn't contribute to the self-attention mechanism. In Pytorch, this is done by passing src_key_padding_mask to the transformer. For the example, this looks like [False, False, False, False, False, False, False, True, True, True] where the True positions should be masked. The output of the encoder is called memory.
for i, sentence in enumerate(batch):
masks.append([False for _ in range(len(sentence))] + [True for _ in range(seq_length - len(sentence))])
batch[i] = sentence + [0 for _ in range(seq_length - len(sentence))]Padding and masking is taken care of in the dataset class
The Decoder
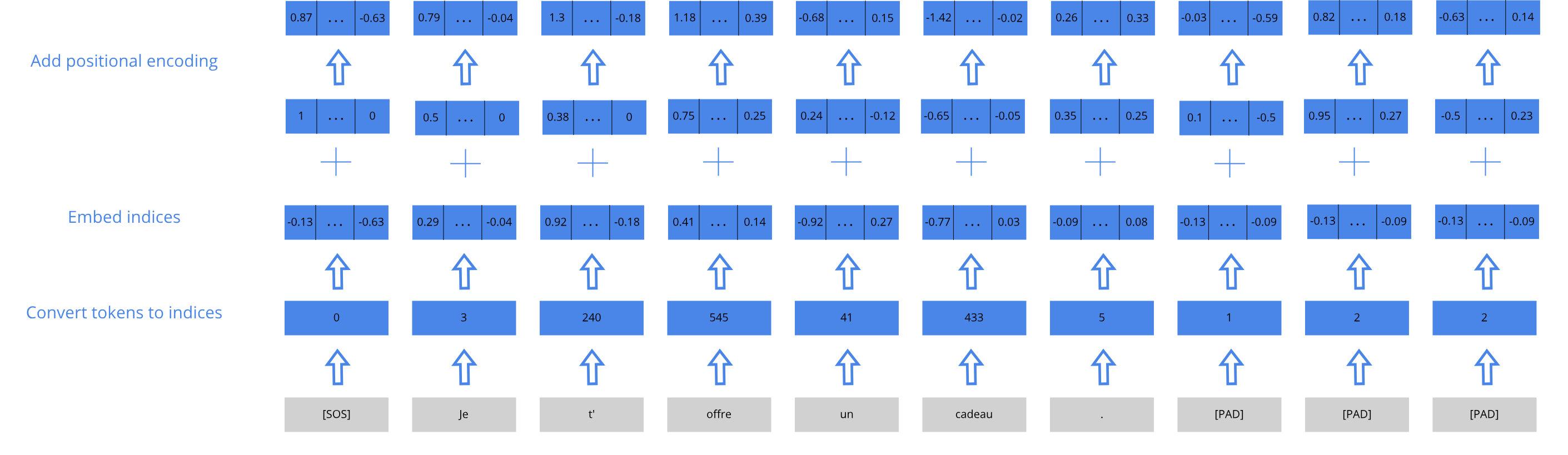
Input to the decoder
Now we can move onto the decoder architecture. The initial steps are very similar to that of the encoder. We embed and pass all but the very last token of each sentence into the decoders.
self.embed_tgt = nn.Embedding(vocab_size, d_model)
tgt_inp = tgt[:, :-1]
tgt = rearrange(tgt_inp, 'n t -> t n')
tgt = self.pos_enc(self.embed_tgt(tgt) * math.sqrt(self.d_model))In the LanguageTransformer class, we embed and encode the target sequence
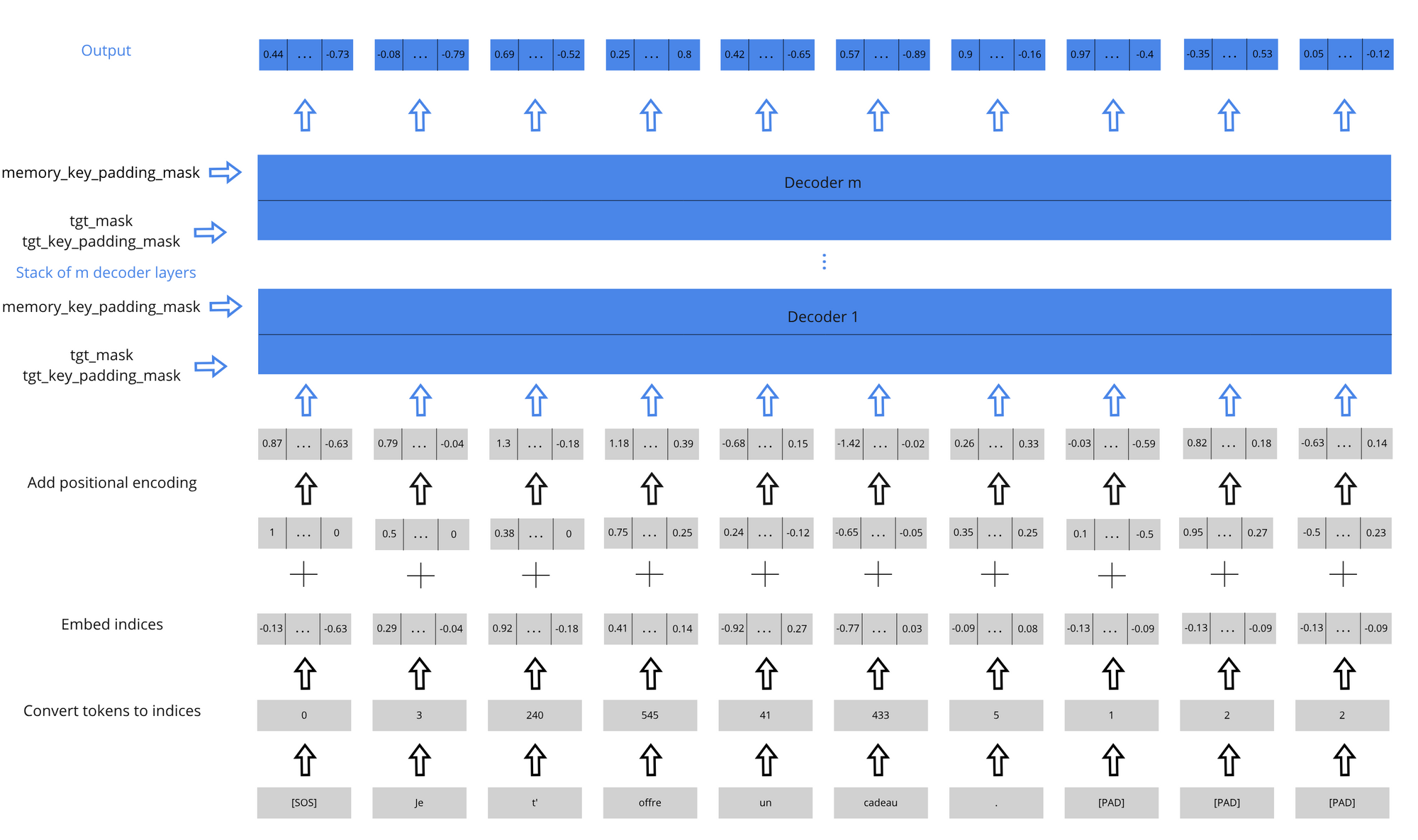
Transformer decoder
We then pass these sequences through m decoders. In each decoder, the sequences propagate through self attention and then attention with the memory (from the encoder). So the decoder requires 3 masks:
- tgt_mask: Used in the self-attention, it ensures the decoder doesn't look at future tokens from a given subsequence. This looks like [[0 -inf -inf ... ], [0 0 -inf ...] ... [0 0 0 ...]]
- tgt_key_padding_mask: Also used in the self-attention, it ensures that the padding in the target sequence isn't accounted for.
- memory_key_padding_mask: Used in the attention with the memory, it ensures the padding in the memory isn't used. This is the same as the src_key_padding_mask
def gen_nopeek_mask(length):
mask = rearrange(torch.triu(torch.ones(length, length)) == 1, 'h w -> w h')
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
memory_key_padding_mask = src_key_padding_mask.clone()
tgt_mask = gen_nopeek_mask(tgt_inp.shape[1]).to('cuda')This is in the train method. src_key_padding_mask and tgt_key_padding_mask is expected from the dataloader
Afterwards, we pass each of the output sequences through a fully connected layer that outputs a probability for each token in the vocab size.
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, trans_dropout)
output = self.transformer(src, tgt, tgt_mask=tgt_mask, src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask)
output = rearrange(output, 't n e -> n t e')
output = self.fc(output)This is in the LanguageTransformer class
And here is the completed LanguageTransformer class!
class LanguageTransformer(nn.Module):
def __init__(self, vocab_size, d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, max_seq_length, pos_dropout, trans_dropout):
super().__init__()
self.d_model = d_model
self.embed_src = nn.Embedding(vocab_size, d_model)
self.embed_tgt = nn.Embedding(vocab_size, d_model)
self.pos_enc = PositionalEncoding(d_model, pos_dropout, max_seq_length)
self.transformer = nn.Transformer(d_model, nhead, num_encoder_layers, num_decoder_layers, dim_feedforward, trans_dropout)
self.fc = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt, src_key_padding_mask, tgt_key_padding_mask, memory_key_padding_mask, tgt_mask):
src = rearrange(src, 'n s -> s n')
tgt = rearrange(tgt, 'n t -> t n')
src = self.pos_enc(self.embed_src(src) * math.sqrt(self.d_model))
tgt = self.pos_enc(self.embed_tgt(tgt) * math.sqrt(self.d_model))
output = self.transformer(src, tgt, tgt_mask=tgt_mask, src_key_padding_mask=src_key_padding_mask,
tgt_key_padding_mask=tgt_key_padding_mask, memory_key_padding_mask=memory_key_padding_mask)
output = rearrange(output, 't n e -> n t e')
return self.fc(output)Results
I used the tatoeba dataset, a small dataset with around 160000 english to french language pairs available here.
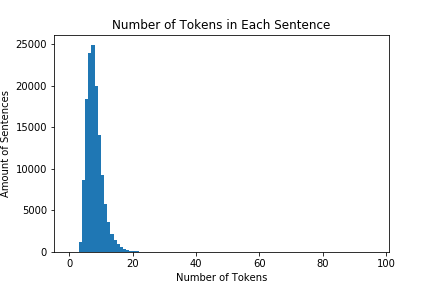
A relatively small dataset with short sentences
Here are the results of training for 20 epochs:
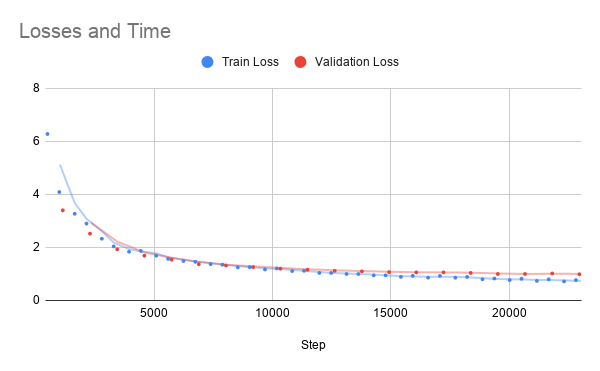
Losses vs Time
My model achieves a validation loss of 0.99. However, it starts overfitting around epoch 15 based from the validation loss being higher than the train loss. And finally, some results of translating sentences:
I am giving you a gift.: Je vous donne un cadeau. How did you find that?: Comment l'as-tu trouvée? I'm going to run to your house.: Je vais courir à votre maison.
Further Research
Some improvements that could be made:
- Using beam search to translate sentences
- Running the model on larger datasets
- Using torchtext instead of hacking my own dataset class to get more consistent batches
- Using smoothened loss
My code is located here.